許久沒有寫博客了,不知不覺也來到美國快一年了,感觸頗多,我會在入職Google一週年的時候在寫個博文講述在Google的工作生活,這(幾)篇博文主要是來紀念下曾經的旅遊經歷。
2013年3月份,曾有幸來到蘇州,一睹美麗的江南風光,精緻的園林,復古的古街,無一不透露著江南的秀氣。在配上3,4月份的春雨,實乃人家美景啊。





The story of coding…
許久沒有寫博客了,不知不覺也來到美國快一年了,感觸頗多,我會在入職Google一週年的時候在寫個博文講述在Google的工作生活,這(幾)篇博文主要是來紀念下曾經的旅遊經歷。
2013年3月份,曾有幸來到蘇州,一睹美麗的江南風光,精緻的園林,復古的古街,無一不透露著江南的秀氣。在配上3,4月份的春雨,實乃人家美景啊。
这一次我们阅读和翻译关于分层实验平台的来自Google的论文Overlapping experiment infrastructure: more, better, faster experimentation (没有找到特别官方的链接,学术搜索能搜到)。
Google也大量需要在线的对照实验来做决策,几乎所有的微小的改变,都需要通过实验决定。相比众多的实验,流量的数量已经成为了瓶颈。为了更高效、更准确地做更多的实验,这篇文章设计了分层实验平台。同一份流量可以同时做多个实验。
更多、更好、更快
实验平台不仅能同时运行多个实验,也要具有灵活性:不同的实验可以使用不同的配置、不同的流量大小。不正确的实验不应当被允许运行,正确但影响很差的实验应当被迅速发现并中止。实验的设置和进行应当容易并迅速,即使不是工程师也可以做(不需要写代码)。实验指标应当实时可用,这样实验就可以被迅速评估。简单的重复实验应当很容易做,最理想情况下,实验平台可以用做灰度发布(gradually ramping up)。
发展到这一步,不仅需要工程上的架构设计,也需要相应的工具和对使用流程的控制。
背景
这里说的分层实验平台只用在Web互联网服务上,不包括Google Apps、Chrome等(我们可以想象一下,实际上,非Web服务也可以做对照实验,但是如果要做重叠的实验则有一定的困难)。
与之前在(一)中提到的对照实验系统一样,做对照实验完全由参数来控制。使用参数使得实验容易创建,因为他们可以是易读的文字,不是代码。同样,数据文件比程序文件更容易快速部署。
在最初,Google使用了一种可以称作“单层实验平台”的架构。一个流量只能做一个实验。首先分配基于Cookie划分流量的实验,然后再划分基于随机分配流量的实验。这种架构不足以支持足够多的实验。
分层架构
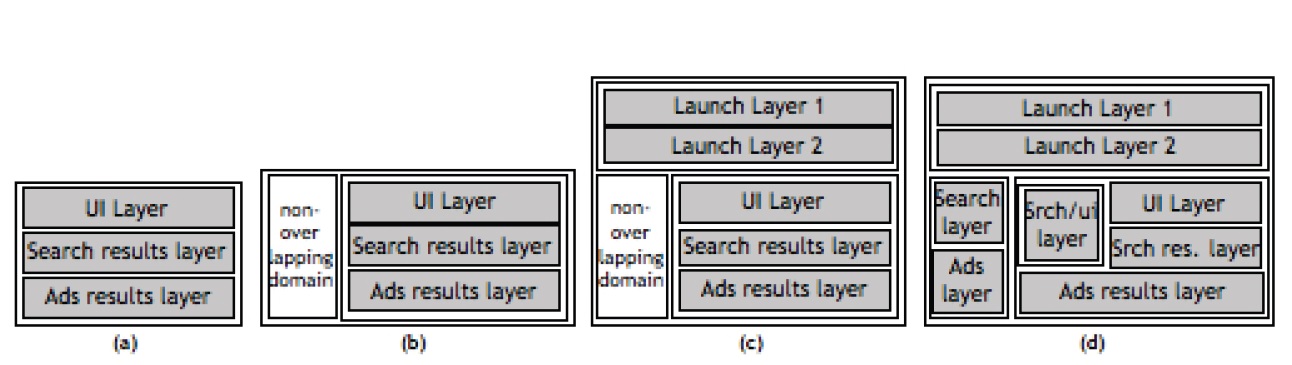
我们将参数划分为若干个子集,每个子集之内的参数是可能互相影响的,也就是说不能同时做实验的;子集之间的参数则是不会互相影响的(正交的)。这种划分可以来自于检查,也可以来自于过往实验的结果。用每一个子集对应一个抽象的“层”的概念。同时,把对流量的每一个划分抽取对应一个抽象的“领域”(domain)的概念。一个领域里可以有多层,一个层里也可以有多个领域。如图。而这个图也可以看做最宏观上Google Web的层和领域的划分。
虽然看起来有点复杂,但这个划分有很多好处。一个非重叠实验领域,可以方便地做影响非常大的实验(可能实验的参数跨遍各层,只能在这个领域做);它允许在两个领域中对相同的参数做不同的划分;我们也可以比较容易地把一个参数从一层中移到另一层中(如果发现这样更有利于流量的利用)。
注意到图(c)中增加了发布层Lanuch Layer。Lanuch Layer是一种特殊的层,它们必须运行着100%的流量(它们所在的领域称default domain,不能与其他domain纵向切分),同一个参数最多出现在一个Launch层中,同时最多出现在一个普通层中。Launch中参数的取值,可以被下面普通实验层中进行的实验的参数取值所覆盖。
发布层的典型应用是,每一个待发布的参数版本,新建一个发布层,而当它稳定后,删掉这个发布层。由于发布层在default domain中,因此它可以用来最终验证实验间的相互影响。
流量的划分不仅有基于cookie、random的,也会根据实验的要求有更灵活的其他方式,比如userid,query-string等。而不同的划分方式可能会在领域与层之间造成饥饿和有偏的问
题,为此,需要给每个领域和层指定流量划分方式,对已经被上层抽取造成的有偏的流量要加以标识,排除掉它们以避免有偏。
分层实验框架的工程架构基本就是如此,而这篇论文的后半部分还用了很大的篇幅讨论前面说到的”工具和使用流程控制”,我们在下一篇阅读笔记中讨论。
Link如下:
Proto Visualizer

以前为前东家打工的时候,通信协议主要是json(其实是二进制化的json),然后查问题基本只靠这个神器:
Json Visualization
这样繁复的json可以瞬间转化成可视化的表格,事半功倍。并且所有的转换操作都是在浏览器里面做的,也不用担心安全问题。
但现在的工作已经很少用到json了,反而是越来越多地使用pb,但pb这个的文本格式也不是很好读,并且有时候为了把一条信息打印到一行中,不得不使用ShortDebugString(), 这样使得文本更难看懂……
然后今天突然想到一个idea,既然网上那么多json visualization的工具,是不是我可以来一把曲线救国,先把pb转换成json,这样不就成了!
然后就真的找到了一个js版本的lex-yacc, http://zaach.github.io/jison/ , 然后我就写了这样的语法规则:
/* description: Proto2Json Converter */
/*lex*/
%lex
%x string
%%
s+ /* skip whitespace */
[-0-9]+("."[0-9]+)?("e+"[0-9][0-9])?b return 'NUMBER'
[a-zA-Z0-9_x5Dx5B\.]+ return 'ID'
"{" return '{'
"}" return '}'
":" return ':'
""" this.begin('string');
/*""" this.popState();*/
(\"|[^"])*""" this.popState();yytext = """ + yytext;return 'STRING';
<> return 'EOF'
. return 'INVALID'
/lex
%start expressions
%%
expressions
: object EOF
{ console.log(JSON.stringify($1, null, 4)); return $1;}
;
object
: kv_list
%{
result = {}
$kv_list.forEach(function (kv) {
k = kv["key"];
v = kv["value"];
if (result[k] != undefined) {
if (result[k] instanceof Array) {
result[k] = result[k].concat([v]);
} else {
result[k] = [result[k]].concat([v]);
}
} else {
result[k] = v;
}
});
$$ = result;
%}
;
kv
: key_type ":" literal_value
{$$ = {"key": $key_type, "value": $literal_value};}
| key_type "{" object "}"
{$$ = {"key": $key_type, "value": $object};}
| key_type "{" "}"
{$$ = {"key": $key_type, "value": {}};}
;
key_type
: ID
| NUMBER
;
literal_value
: NUMBER
| STRING {$$ = eval($STRING);}
| ID
;
kv_list
: kv
{$$ = [$kv];}
| kv kv_list
{$$ = [$kv].concat($kv_list);}
;
发现其实没有原来想得那么麻烦, 与其不停期盼为啥没这么一个工具,不如自己动动手。
blog也好久没新文章了,锄锄草。
原始文章传送门 http://www.gruter.com/blog/?p=391
General Feature
数据往往以RC & ORC & Parquet等格式存放在HDFS 以及在分布式环境上执行SQL
SQL-on-Hadoop solutions
1. Hive: 将SQL转成MapReduce Job,继承了MR的稳定可靠,同时也带来了Shuffle过程的额外消耗
2. Stinger: 将计算框架迁移到Tez上, 因此并不算是一个独立的新解决方案,但可以解决Hive一部分不足
3. Apache Iajo: 在HDFS上使用了自己的分布式执行引擎
4. Impala: 使用了自己的分布式计算框架,在Shuffer阶段会将所有数据保存在内存中,因此避免了shuffling overheads, 但是不能处理超过内存限制的数据量
5. Apache Drill: Google Dremel的开源实现,目前还在开发中,而且还没实现其主要的分布式处理模块
Key SQL-on-Hadoop performance factors
1. 磁盘扫描速度,因为数据通常是存放在HDFS;此外中间数据的传输效率也是个重要因素,因为像Group By或者Order By之类的算子往往会以多步来执行
2. Query Execution启动时间,对于短查询而言,启动时间会成为较大的OverHeads,而在长查询中,启动时间往往占比很小
3. 文件格式,目前有 RC & ORC & Parquet等,往往这些文件格式有不同的特性,往往需要根据实际的应用场景来选择合适的文件。Query往往会生成大量的结果文件,文件格式和文件写效率是一个关键的因素,比如ORC文件格式有较好的读性能,但是写性能较差。此外合适的压缩机制也是一个关键因素在SQL-on-Hadoop系统中
The absolute performance limits of SQL-on-Hadoop
1. 除了上面的因素之外,还有一些限制是不能超出的:处理性能会小于或者等于在HDFS上的磁盘带宽
2. 对于像Select count(*) from table这样的查询而言,由于没有shuffle消耗,因此磁盘读取速度,Query启动时间和文件格式成为关键因素,当使用相同的文件格式和大量的数据场景下,各个解决方案的时间相差不远
3. 对于across a range of natural field queries, Stinger这些只是比Hive快1.5-3倍左右
Frequently-used performance comparison queries
1. 对于短查询而言,Stinger由于省去了启动时间,因此可能会比Hive快上百倍,但是并不意味着在长查询中也有同样的效果
2. 而对于Order By这类操作,Hive只用单机来执行,对于能够分布式Order By方案而言,查询效率是能够比Hive高上千倍的,只要节点数足够多。但是并不能就宣称比Hive快上上千倍
来源于Google在sigmod2013发表的一篇Photon: Fault-tolerant and Scalable Joining of Continuous Data Streams http://www.mpi-sws.org/~areznich/files/photon-sigmod13.pdf
主要是描述了广告系统中展现流和点击流如何实时Join的问题
Introduction
1. 对于Google Adwords这类的商业系统而言,能够近实时的反馈广告主的预算消费等多维度的统计数据,能够使广告主及时知道调整投放策略后的效果以及允许Google内部系统更有效地优化budget-Control策略
2. Photon会从不同数据中心的GFS读入Query Log 和 Click Log后,根据query id Join后生成新的log写到不同数据中心的GFS上
3. 需要注意到单独的展现流或者点击流是不能包含报表统计所需要的所有数据的。一种解决方式是将展现信息带到点击串中,但这样会存在不少问题:一来点击串带上额外过多的数据会增大响应延迟和降低用户体验,二来点击URL是有长度限制的,限制了我们所能够带的数据量的大小
Problem Statement
1. 解决的问题:有两条持续增长的数据流,在primary log里每条日志有唯一的identifier,而foreign log里也带有同样的identifier用来与primary log做Join操作
2. 在传统数据库里,上述场景类似于foreign table 根据外键与primary table做inner Join,点击流可以类似于foreign table,展现流类似于primary table,query_id作为Join Key
System Challenges
1. 数据的不重不丢:重复数据将会导致广告主重复计费,丢失数据将会使Google收入减少。Photon保证99.99999%的数据会在秒级别被Join到输出,100%的数据会在小时级别后被Join到。因此Proton需要满足:在任意时候最多只处理一次的语义、准实时的处理一次语义以及最终的不重不丢语义
2. 数据中心级别的自动容错机制:数据中心服务有时候会中断服务,有计划内也有计划外,比如软件升级或者机房异常断电,这个中断服务的时间有可能是分钟级别,也有可能达到了数周的级别。因此在出现故障后,很难决定是在其他数据中心迁移服务还是等待原服务恢复正常,这会极大降低系统的可用性。GFS这类系统在小规模机器故障时能够运行良好,但是在设计时候没有考虑数据中心级别的容错,因此需要应用层用户考虑更多的事情。考虑到Proton的可用性是会直接影响到公司的收入,因此Proton需要数据中心级别的自动容错机制
3. 高可扩展性:Proton不只是要能够分钟数百万的数据,还需要能够应对未来流量的持续增长
4. 低延迟:Proton的输出用于为广告主生成报表,更低的延迟能够便于广告主更有效的优化预算投放等操作
5. 非严格时序的数据流: 展现数据流是根据query timestamp基本有序到达的,但点击数据有天然延迟,不一定是按照query timestamp有序到达,因此使用Window Join的方式比较困难
6. 展现数据流的延迟:虽然展现行为是早于点击行为,但由于展现数据量比点击数据量大同时是分布在不同数据中心等各种原因,展现log不一定先于点击log到达Proton。因此需要处理这种延迟情况
Paxos-Based Id Registry
1. 在分布式系统中,提供可靠性最直接的方式就是增加副本。类似于线上检索系统,为了提供数据中心级别的可靠性,往往会在不同的数据中心部署同样的服务。Proton也会在不同的数据中心部署相同的worker,尝试去Join同样的输入,但是会保证每个输入input event只会被处理一次。不同worker之间会共享存储在Id Registry上的全局状态:最近N天内已处理过click_id的集合,N的选择取决于资源消耗和丢失数据影响面的trade-off。需要注意到当系统遇到延迟到达N天之前的数据,由于没有办法去判断这批数据是否已经被Join过,为了防止重复计费,所以需要选择丢弃不处理
2. 在输出Join后的数据前,每个worker需要先验证对应的click id是否已经在Id Registry,如果已在则丢弃数据,否则需要尝试去往Id Registry写入click id。只有当写成功后,才能够输出Join后的日志。Id Registry需要保证click id一旦被写入,后续的写同一个click id的操作都会失败。
3. Id Registry需要提供数据中心级别的容错,多个副本的数据在不同的数据中心实时同步,可以容忍可配置的N个数据中心级别的服务停止。同时要保证写操作能够成功当且仅当对应的click id在Id Registry不存在。
Id-Registry Sever Architecture
1. Id Registry是建立在PaxosDB基础上: 一个内存型的key-value存储,通过Paxos协议来保证多副本之间的一致性,之外还提供了read-modify-write transaction来保证同样的key只有一次写入会成功
2. PaxosDB保证副本是按照同样的顺序去处理submitted values, 同时在任意时刻只有一个副本能够成为master,也只有master能提交更新到Paxos. 如果master出现故障,PaxosDB会自动选举出一个新的Master
3. Id Registry Server会有RPC Handler Thread接收client端请求,然后放到内存队列中,同时会有另外background 线程从队列中取出请求,往PaxosDB执行事务操作,并返回结果给Client
Scalable Id-Registry
1. Id Registry提供了数据中心级别的容错,一个commit操作需要经过分布在不同数据中心的replica agree后才能提交,而由于跨数据中心的网络交互延迟在100ms左右,因此会限制 Id Registry的吞吐只能是10个请求每秒, 这是远小于系统的预期。虽然可以通过client批量提交请求来缓解,但由于client端太多,这种机制不能彻底的解决问题。Id Registry使用了Server-Side Batch 和 shading的方式来解决扩展性问题
2. Sever-Side Batch: 系统内部处理的延迟其实主要来自于跨数据中心拓扑带来的交互延迟,而不是在于数据量的大小。因此Id Registry的background线程可以从队列里取出多个请求并作为一个事务提交(类似于Group Commit)。由于一批请求里可能会有对同一个key的写操作,因此Id Registry也提供了多行事务的机制,保证第一个写入才会返回Client成功,其他写入会返回失败。由于一个click id不会超过100个字节,因此background线程一次可以batch上千个请求来提交
3. Sharding: 由于Click id之间的处理是独立的,因此不同的click id可以由不同的Server来处理。当存储数据出现增长时,Id Registry需要支持动态扩容, 只是简单扩shard的方式会使得取模分库的方式出现错误,因为同一个click id会在扩容前后分布在不同的库上,导致有可能重复输出。因此需要一个确定性的mapping机制,在保证能够动态扩容的同时又可以向后兼容来保证数据的一致性。Id Registry使用了time stamp-based shading Configuration机制来解决这个问题。
每一个click id都会被赋予一个时间戳,在扩容期间,给定一个时间间隔S(需要保证当时处处理的click id之间的时间戳之差不会超过S),如果当前时间是T,那么时间戳小于T+S的数据mod旧的分库数,而时间戳大于T+S的数据mod新的分库数。这个sharding配置将会村存储在PaxosDB, 被所有的Id Registry Server和Client端共享。另外,缩容的时候可以采用一样的方式来处理。
4. Deleting Old Keys: Id Registry只保留N天的数据,N称为garbage collection threshold。为了删除过期数据,每个库的master实例会有回收线程周期性扫描过期的数据并删除,同时为了保证master切换时的时间同步问题,garbage collection boundary times tamp 会存储在Id Registry里,同时每个实例会有另外一个线程利用TrueTime机制周期性更新times tamp ,保证不会出现时间戳回退现象。如果Client尝试查询或者删除过期数据,Server会返回一个特殊的错误码,让Client跳过当前数据的处理。
Single Datacenter Pipeline
1. Photon在每个数据中心的Pipeline大致会分为以下几个部分:dispatcher负责读取click log并分发请求到Joiner,EventStore提供高效查询Query log机制,Joiner负责从EventStore度读取query log与当前的click log做Join,并利用Id Registry去重和输出Join后的结果。整体处理流程会分为以下几步:
1) Dispatcher从GFS持续读取日志,并查询Id Registry是否对应的click id已被处理过。如果被处理过,则跳过当前的点击日志
2) 如果没有被处理过,则异步地分发到Joiner并等待结果。如果Joiner处理失败(比如网络或者对应的Query log不存在) ,Dispatcher会在一定周期后再分发到其他Joiner
3) Joiner会从click log抽取出Query Id,并在EventStore查找对应的Query log
4) 如果查找不到,Joiner会返回失败给Dispatcher. 如果查找成功,则Joiner尝试往Id Registry插入click id
5) 如果click id如果已经存在于Id Registry,则Joiner认为对应的click log已经被Join。如果能够成功写入,则会Join完query log和click log后写出到GFS
Unique Event Id Generation
1. 由于会有成千上万的线上Server部署在全世界,因此能够快速生成一个全局唯一的ID对系统的处理延迟是非常重要的, 而每个Server独立生成ID的机制是满足这个特点
2. Event Id是个三元组: Server IP + Process IP + Timestamp。每个Server会基于当前的时间为每个event生成递增的Times tamp。由于Timestamp的生成会收到时钟频率的影响,为了保证正确性,还需要有个后台线程周期性调用TrueTime API同步时钟
Dispatch: Ensuring At-Least-Once Semantics
1. Dispatch会周期性扫描日志目录里的成千上万的日志文件,监控是否有新的日志产生。为了提供并发度,Dispatch会有多个worker并行去处理不同的日志文件,同时将各自的处理进度保存在GFS。在发送log event到Joiner之前,会先在Id Registry查询click id验证对应的日志event是否已经处理过,这个优化技巧可以极大的提高系统处理性能
2. 当Dispatch接收不到Joiner的返回处理成功的消息,会将click日志保存在GFS并稍后尝试。为了减少由于连续处理失败(比如网络拥塞)引起的重试比例,Dispatch会使用类似于指数退避的算法。如果Joiner重试了多次仍然失败,并且click log的时间老于某个阈值,Joiner会将日志表示unjoinable,并返回成功给Dispatch
3. 当一个数据中心停止服务后,这个不会影响Photon服务的可用性,因为至少有另外一套在其他数据中心并行运行.当数据中心服务恢复后,Dispatch会读取进度状态重新开始发送日志,由于大多数日志在其他Pipeline已经被处理过,所以Dispatch会在Id Registry查询到这批日志已经被处理过,将可以跳过这些日志并会很快追上当前进度。Dispatch将会采取流控策略保证不会给Id Registry带来过大压力,同时能够保证足够快的恢复速度。如果进度文件已经损坏,可以人工清空状态并从最新文件开始处理,这需要其他Pipeline保证在此之间一直没有停止服务
Joiner
1. Joiner在EventStore查找不到Query log或者自身压力过大时会返回处理失败给Dispatch。当能够查找到Query log时,Joiner会将展现日志和点击日志传递给一个日志处理的lib库Adaptor,Adaptor会做过滤、拼接或者用户自定义操作等,将业务逻辑从Joiner分离能够极大提高Joiner架构的灵活性
2. 当Joiner往 Id Registry插入click id失败时(由于之前有click id插入成功),则Joiner会丢弃这条日志,这种情况被称为wasted Join, 由于至少有两个数据中心在同时运行,因此同一条日志在系统内部至少被处理两次,为了减少wasted Join的比例,Dispatch在下发数据前会先有查询操作。与Dispatch不同,Joiner没有任何状态,因此Dispatch可以采取均衡策略将请求分发到任意的Joiner
3. Joiner在写Id Registry和写日志数据到GFS两个操作之间的非事务性特性会导致数据出现丢失风险。一般可以分为两种情况
1) 其中一种情况是Joiner超时或者没有由于网络原因没有接收到Id Registry的返回结果。当重新发送请求时,由于click id已经存在将会导致Id Registry返回处理失败,Joiner将会丢失这条日志。为了解决这个问题,当Joiner commit一个click id到Id Registry时,同时发送一个全局唯一的token(包括ip + 进程号 + 时间戳)到Id Registry。Id Registry会同时将click id和token一起保存。当Joiner接收不到Id Registry的返回结果重试时,会带上同样的token,当Id Registry检测到token一致时将会返回成功给Joiner
2) 另外一种情况是写Id Registry成功,但在写日志数据到GFS之前Joiner出现宕机。这种情况将会导致click log不能再被其他Joiner Commit,因为click log所对应的token已经不属于任何一个Joiner。为了减少这种情况的影响面,每个Joiner会限制当前要被处理的请求个数,一旦达到上限,将会返回失败给Dispatch。
4. 丢失数据的场景还会有logs Storage丢失数据或者软件bug之类,Proton提供了一个校验系统来作为系统的数据一致性保证。检验系统会读取原始输入click log,并检查是否在Join后的输出文件里,如果发现不在输出文件,但是对应的click id在Id Registry,校验系统将读取tokon中的数据来判断对应的Joiner是否已经宕机或者重启,如果发现Joiner已经宕机或者重启,检验系统将会在Id Registry删除对应的click id并将原始的click log重注入到Dispatch。由于检验系统只是需要读取丢失数据的token,所以可以在Id Registry里删除已经输出的数据的token,通过这样的方式可以减少系统所需要保存的数据量。
EventStore
1. EventStore主要是提供了根据query id返回query log的服务,在Photon系统中提供了两种EventStore的实现,一种是CacheEventStore,主要利用event的时间局部性(大部分点击行为都是在展现后短时间内发生),另外一种是LogEventsStore,主要利用query log在日志文件中是近似按照timestamp有序保存
2. CacheEventStore是一个内存型cache,与分布式memcache相似,key是query id,value是query log,sharding规则是根据query id做一致性hash,cache的过期时间是分钟级别。其中CacheEventStore极大优化了读取延迟以及减少在LogEventsStore的随机IO读写
3. LogEventsStore会通过读取保存在BigTable里的log file map来获得对应的query log在原始日志文件里的大致位置,从近似位置开始store会顺序读取一小部分数据来找到确切的数据。log file map里面保存了query id与文件路径及偏移的映射关系,EventReader会按照固定的间隔,比如每隔W秒或者M Bytes数据就会往log file map添加新的记录,EventReader同时是会往CacheEventStore填充数据。Bigtable提供了Range Query机制,因此Store会在Bigtable里扫描key在ServerIp:ProcessId:Timestamp-W到ServerIp:ProcessId:Timestamp之间的数据,只要reader按照固定周期更新log file map,就可以保证总可以通过一个记录找到实际的log
Performance Result
1. IdRegistry部署在三个地域的五个数据中心,每个地域最多有两个副本。由于只要有3/5的副本投票成功便可以commit操作,因此可以容忍一个地域的服务出现故障
2. Dispatcher之类的服务会部署美国的东西海岸,同时会与log datacenters物理上很接近
3. IdRegistry会有上千个分库在每个数据中心,同时在每个数据中心,Photon系统会有上千个Dispatcher&Joiner服务。Photon每天能够T级别的点击数据和几十个T级别的展现数据
4. 从读取原始日志到生成Join后日志,90%的处理延迟小于7s,之外还有cache命中率高、较好的数据中心级别的自动容错机制、吞吐能力强等特性
Design Lessons
1. 基于Paxos建立一个分布式系统,需要减少保存在Paxos上的元数据, 因为在不同数据中心之间同步数据的消耗是非常昂贵的
2. 为IdRegistry提供动态扩容机制能够极大系统的可扩展性
3. 通过RPC交互方式相比于数据通过磁盘交互能够极大降低延迟,但是应用层需要处理RPC失败或者重试等场景。同时为了避免系统的过载,让Dispatcher来负责整体的重试机制,能够使得其他worker通过RPC交互极其灵活
4. 模块的单一职责能够使的系统更具有可扩展性,在旧系统里Joiner和LogEventsStore的功能合并在同一个Worker,同时还CacheEventStore,这极大限制了系统的处理能力
5. 其他类似的系统是将多个event作为一个batch来处理,但是这些系统运行稳定要依赖于在一个batch里的所有event都能够同时处理成功。由于在Photon里的应用场景里,展现有可能延迟于点击,因此除非所有query log都已经到达,否则一个batch是不能commit的。因此在设计时需要根据具体的场景来考虑是否需要batch
Future Work
1. 将Phonton扩展成能够处理多流的Join,以及进一步降低处理的延迟:通过server直接发送query event和click event到Joiner,而不需要Dispatcher等日志拷贝到数据中心,这能够使大多数的数据得到最快的处理,剩下的missing event则交给原有的logs-base系统来处理
来源于Google在vldb2013发的流式计算框架论文MillWheel: Fault-Tolerant Stream Processing at Internet Scale
http://db.disi.unitn.eu/pages/VLDBProgram/pdf/industry/p734-akidau.pdf
Introduction
1. 实时计算一般可用于实时反作弊或者异常监控等场景,需要 fault tolerance & persistent state & scanlability
2. MillWheel 提供了良好的编程模型和流式计算框架,对用户屏蔽了分布式、容错等各方面 细节,保证数据的不重不丢。同时提供优雅的保存处理进度机制
3. 其他流式系统不能同时满足容错、通用性和扩展性特点。比如 S4 不能保证数据不丢,而 Streaming SQL System (比如Spark Streaming) 在应对复杂的业务场景下SQL语言表达能力不足
Motivation And Requirements
1. 应用场景google内部的Zeitgeist系统,用来监控检索Query的流量是否突增或者突降。主要是通过模型预测值与实际值做对比。
2. Persistent Storage: 有短期的时间窗口存储需求和长期的数据存储需求
3. LowWatermarks: 用来追踪分布式环境中所有等待处理的events,可以区分数据是延迟还是真的缺失。同时也可以规避应用场景中需要按照数据的严格时间序来处理数据
4. Duplicate Prevention: 保证数据不会被重复处理 ,除了保证不会出现突增的误判外,在计费系统也是有同样的需求
5. MillWheet 提供了数据的不重不丢机制,能够优雅处理out-of-order数据,同时提供可靠存储,系统内部计算递增的LowWatermark等特性
System Overview
1. MillWheet可以认为是一堆算子组成的DAG图。这些算子可以跑在任意数量的机器上,所以用户不需要关心load balance方面的事情.同时可以支持动态调整拓扑,而不需要重启整个集群服务
2. 数据模型是使用一个三元组表示(key,value ,timestamps) 。算子可以自身的业务逻辑来定义处理的key,value可以是任意的二进制串,timestamps用户可以填任何的数值,但是通常是事件发生的clock time, 系统内部会根据timestamps来计算LowWatermark
Core Concerts
1. Computations: 用户的逻辑运行在算子里,当数据到达后,用户的逻辑将会被触发。如果用户的逻辑需要跟外界系统交互,需要自己保证在这些系统上的操作是幂等的。应用层的处理逻辑不需要关心Key会被不同的节点并行处理。
2. Keys: Keys是系统中最主要抽象的概念,通过定义不同的key extraction function,不同的消费者可以从同一个输入流抽取出不同的key,比如在Zeitgeist系统中可以将Query作为key,但在反作弊系统可以用Cookie来作为Key
3. Streams:Streams是不同算子之间的交互机制,一个算子可订阅一个或者多个Stream,也可以发布一个或者多个Stream
4. Persistent State: 持久化存储的内容通常是byte string,用户可以通过Protobuf之类的来序列化或者反序列。后端的存储系统满足了高可用、多副本等特性(Bigtable or Spanner)等,一般的应用场景是一段时间窗口内的Counter或者不同数据流之间的Join操作
5. Low WaterMark: lwm是个时间戳,反映了数据到达算子A的时间界,而一个算子A的 lwm定义为
min(oldest work of A , low watermark of C : C outputs to A)
C是算子A的上游算子,如果A没有输入Stream, 则lwm与oldest work相同, 其中oldest work of A 是指还没A处理的内部数据的最老时间戳。
MillWheet的数据导入系统Injector在每次导入数据时会设置数据源的lwm,但是这只是个估算值。因此内部系统可能会收到一小部分时间戳较旧的数据,可以根据自身的业务逻辑选择丢失或者更新内部累积量。但这里需要注意到,即使出现了老数据,lwm仍然保证是递增。
lwm的作用在于系统可以告诉用户逻辑某个时间点之前的数据已经到齐, 为了保证lwm的准确性,在用户处理逻辑里,当每次生成一个新的record或者聚合多个record时,用户给这些records赋予的timestamp不能小于源record
6. Timers: 钩子函数,在特定的wall time 或者 lwm value被触发, 用户层可以自身的业务场景是wall time还是lwm, 比如监控系统可以使用wall time触发来在固定的时间发监控邮件,而Zeitgeist系统可以使用lwm来判断是否出现流量突降。此外用户可以选择不设置Timers, 比如判断突增时,数据延迟到达往往不会影响判断的准确性。Timer被设置后,会按照递增的timestamp顺序被触发,同时会持久化到可靠存储里
API
1. Computation API: 用户一般只是需要实现ProcessRecord和ProcessTimer两个函数, 同时框架还提供了SetTimer & ProduceRecord等函数供调用
2. Injector and Low WaterMark API: lwm在算子框架内部会被自动计算(计算的pending work包括了in-progress and queued deliveries),用户逻辑一般不会直接访问lwm,而是通过设置record的timestamp间接影响; Injector在G内部一般是通用的组件,通常会有不同的实例部署在不同的机器上,而Injector的lwm会将这些值给聚合起来,一般情况下会使用还没发布完的输入文件的最老创建时间作为一个实例的lwm
Fault Tolerance
1. Exactly-Once Delivery: 在算子收到一个输入时,框架层会执行以下几个操作: 1) 输入的去重 2) 业务逻辑的处理,可能会修改timers/states/productions 3) 将修改commit到后端的存储系统 4) 给上游返回ack 5) 将production发给下游
为了保证数据不丢,上游必须需要接收到Ack包后才会停止发送,不然会一直重试,因为可能会出现下游机器故障等情况。当下游接收到重复的数据包后,为了防止重复处理,系统会为所有的records在生成阶段赋予一个全局唯一的ID,在commit阶段会将已处理的id与其他状态一次原子更新到后端。此外,由于本地内存有限,在本地内存中会使用bloom-filter方式加快查询已处理过的集合。这些在后端存储系统中保存的ID集合,在确保没有发送端在重试发送后,会被系统自动清除,一般情况下是分钟级别。而由于外部系统Injector往往会发送延迟数据,所以这部分数据的ID集合清理回收会在推迟到小时级别
2. Strong-Production: 在给下游发送Production数据之前先写Production checkpoint,称之为Strong-Production,否则会出现发送不一致的风险。比如一个算子需要将一个时间窗口当前的累积量发给下游,如果在发送数据但还没收到ack包之前出现宕机,然后到重启后继续retry发送这段时间内窗口累积量发生变化,将会导致前后两次发送的数据不一致。当Production处理成功后,Production checkpoint将会被删除。
3. Weak Productions and Idempotency: 前面的Extract-Once Delivery 和 Strong-Product保证了数据和状态的不重不丢。但由于很多应用场景自身业务逻辑的操作符合幂等的性质,从资源消耗和延迟优化角度考虑,框架层可以跳过输入去重阶段而允许数据重复处理,同时允许写Production checkpoint在发送数据给下游后-框架层的处理逻辑跟之前有些差异,为了保证数据不丢,需要在接收到下游的Ack包后才会返回给上游Ack(这里自己的理解是如果能够成成功给上游返回Ack也不需要再写checkpoint了)
但对于 Weak Productions,需要注意到先接受下游Ack再返回上游Ack的机制在下游处理失败的异常场景下可能会增大整条流水线的处理延迟,因此可以在等待下游的Ack包一段时间后可以先写Production checkpoint,然后理解返回上游Ack,这样的优化机制能够取得延迟减少和总额外资源消耗减少的双重收益
4. State Manipulation: 系统中保存的状态包括了hard-state(在后端存储系统中) 和soft-state(本地内存,一般是本地cache数据或者聚合统计数据)。由于负载均衡或者机器故障等原因,有可能出现两个Worker同时处理同一份数据,然后出现重复写hard-State,造成数据不一致的风险,因此系统会为每次写操作都会绑定一个sequencer token(类似于抢占式机制,新Worker启动后会先令原有token失效), 保证对同一个key只会有一个写端。
而对于管理soft-state,同样需要保证只有一个写端(Single-Writer),考虑这样一种场景:Worker A在还没有Commit状态到后端存储前,新的Worker A-Prime启动从后端存储扫描数据同步到本地内存,然后Worker-A Commit成功然后返回上游Ack,但是A-Prime同步的之前的旧状态数据,导致出现丢失状态情况,最终会导致整个系统数据流处理混乱
System Implementation
1. MillWheel 建立在分布式环境上,每种算子可以跑在一个或者多个机器节点,Streams交互通过RPC方式
2. 由Replica Master来负责负载均衡操作,对于每种算子都将可处理的key集合划分为不同的连续区域,然后分配到不同的节点。同时会根据机器负载情况,将区域进行合并,拆分或者迁移等操作
3. 后端存储系统使用Bigtable或者Spanner,可以提供单行事务特性。对于一个key的不同的相关状态,比如Timers/Pending Productions/Persistent State都会保存到同一行里
4. 当新的worker重启后,需要从后端存储系统读取状态,然后构建本地内存的Timer Heap或者Production Checkpoint队列。为了保证状态的一致性,因此需要框架提供前面所提到的Single-Writer机制
5. 系统内部会有central authority子系统来跟踪所有的lwm并持久到可靠存储。每个进程会计算自身的lwm(包括Pending Production/Timer等数据,即是之前提到的oldest work),然后汇报给central authority。通常情况下由于本地有内存cache,进程在计算lwm时不需要访问Bigtable,因而计算效率够高。
由于每个进程处理的key的范围都是一段区域,所以进程的lwm也是先按自己的区域聚合后才汇报 到central authority,而central authority会判断是否所有的区域都齐全,若某段区域的数据没有收集则会使用上一次的计算值。最后central authority将各个进程的lwm广播到系统内部各个节点。
每个进程都会通过订阅方式获取到它上游算子的lwm数值,然后结合自身的lwm,计算出最后算子的lwm,再在适当的时候触发Timer. 同时为了保证lwm数据的一致性,每个区域的lwm更新同样会绑定一个sequencer token,类似于之前的Single-Write机制。
Evaluation
1. MillWheel在Google里用途广泛,比如生成广告主实时报表时需要Stream Join,也用于谷歌街景的图像处理等场景
2. 在应用场景中一般建议key要划分均匀防止出现了热点数据导致单台机器负载过重成为了系统整体瓶颈。如果数据出现大规模延迟,那么会造成依赖于lwm的Timer迟迟不能被触发,本地内存不能及时计算完后刷到后端存储系统(因为框架层为了性能优化,避免每一次都从后端存储系统读取数据,会在本地内存保存一段窗口内的数据用于统计),最终将会导致系统整体内存出现上涨风险。一般情况下都是限制injector再导入新的数据直到lwm恢复到正常。
对于互联网公司来说,使用对照实验系统(常被称作A/B Testing,Controlled Experiments,与科学研究中常用的对照实验的原理是完全一致的)来做很多决定都是非常有效和必要的。我们有理由相信大规模地、有效地应用对照实验,是Google公司和百度广告系统取得成功的重要原因之一。:)
这篇论文Practical Guide to Controlled Experiments on the Web是2007年Kohavi等人在KDD发表的论文,是比较早期的介绍在互联网系统中应用对照实验的文章,这次我们从这篇论文的翻译和学习笔记开始介绍对照实验系统。
优势
使用对照实验系统被称作“听用户的意见”,这与用户调查不同,用户自己也未必清楚他们的行为在指定的情况下会是什么样,或者他们的体验是好是坏。然而在互联网上面,他们在用鼠标投票,依次做决定比听从“专家”的意见要靠谱和快速。论文中把公司里的专家的意见称作“High Paid Person’s Opinion”,取了个简称叫HiPPO(河马)。-_-|| 事实的确如此,当使用对照实验系统的时候,互联网公司就从争执中解脱了出来,以用户的反馈为向导在可量化的道路上快速地优化创新~~ 可惜这只是理想情况,实践中对实验系统实践的好坏,可以造成巨大的差别。
对照实验
最简单的对照实验系统,是将用户分成50%对50%的两组,一组为实验组,一组为对照组。对指定的指标,比较两组的统计结果,得出实验组的效果。
实验系统的结果评价中存在一个非常重要的统计问题,随机划分用户之后,会产生抽样的误差。可以计算,对于不同的置信水平,要达到不同的实验精度,需要不同的总流量数。对此这篇论文讲得非常简单,我们在以后对其他论文的介绍中会再提到。这篇论文只简单地举个例子,如果要以实验指标相对变化5%为精度,在95%的置信水平下,需要500,000个流量(用户)。需要的流量数与实验精度是平方反比的关系,一般来讲一个改进能提高相对1%已经算是很不错了,所以说需要的流量通常还是相当大的,小流量的系统在这里会非常痛苦,因为这意味着更长的实验时间。
实验的评价标准应当在实验进行之前就确定,换句话说就是用哪些指标做判断应该先选,否则,如果有很多已有的标准,然后在实验过程中看哪个是正面的并且达到了“精度”就认为存在这个效果,就落入了著名的统计学错误“我早就知道了”。而在实践中,这项原则很多人都”不愿意”遵守。
扩展
实验组的流量比例可以逐步扩大,每一个阶段都可以运行相当长的时间,这样可以避免实验组的负面效果或者bug对整个系统造成过大的影响。而这个过程也可以自动进行。其实与这种方法类似的,就是所谓的灰度发布。
实验甚至可以全自动进行,考虑系统中的某些参数是需要不断随时间调整的情况,可以先指定标准,然后随时自动地根据实时实验结果调整参数。
对照实验可以用做程序迁移时的检查,也就是观察一次新的变更是否并不影响用户体验。对于某些公司来说,这可能才是对照实验最重要的用途。
不足
对照实验是有效的,可是却不能带来解释。
短期利益和长期利益不一致的问题。解决这个问题,应当制定更合理的综合性的标准,但是这件事情并不容易做。
先入为主或者新鲜感造成的影响。这是两个相反的效应,为了识别和避免,可以考虑用新用户做一组同样的实验进行对比。
要实验的功能必须先实现。
一致性问题,用户可能会发现他们在使用一个行为不一致的系统。即使按用户抽样也不一定能避免这个问题。
同时进行的实验的相互影响。这篇论文认为实际上这种情况很少发生,这方面的担心常常是过度的。另一方面,可以做自动的检测来判断实验间是否互相影响了。不过,说起来容易做起来难。
信息公开问题。对于较大的改动可能必须要先公布才能开始上线。然而公开的信息可能影响用户行为。
实现
论文中提及的是,使用足够强度的随机算法,将用户根据标签计算散列,并为每个散列准备对应的partition,在抽样时选择指定的partition就可以实现任意比例的抽样。然而这好像并不是一种非常好的实现方式。
对于流量的分派,有三种方法,第一是split,包括物理上的或者虚拟的。物理划分大概是最直接的一种方法,但是这种方法需要一个分布式的配置甚至程序的部署系统。第二种方法是在server端选择,server端程序在处理过程中计算随机函数,并且给出不同的行为。这种方法带来了额外的编程代价,通常变更实验时还需要改变代码。第三种方法是在client端选择,按论文所说,这种是通过JavaScript之类的方法实现的,感觉很受局限,似乎意义不大。
实践中学到的
作者这里引用了一句很经典的话:在现实中理论和现实的差距比理论上要大得多。
对数据做分析:整体上指标的结果只是一个方面,实验实际上提供了丰富的信息可以做研究。不过这里要小心之前提到的”我早就知道了“错误。
性能很重要:不知不觉拖慢了网页的加载速度可能会影响很多指标,程度往往令人惊讶。当你发现实验指标很难解释的时候多想想是否是性能的问题。
是否一次只实验一件事?有些人认为一次应该只实验一件事,作者认为这个限制过于严格了。与之前提到的一样,大多数情况下实验并不会互相影响(真的是这样吗?),另一方面技术上让实验并行又是完全可行的,因此作者建议这样的做法:只对确实很可能互相影响的事情分开做实验。在以后我们也许会讨论实验的并行以及实验间相互影响的检测之类的话题。
持续运行A/A测试:与其他测试同时,持续地运行A/A测试。这可以用来检测用户是否被合理划分,数据是否被正确收集,以及设想的置信水平是否确实可靠。
自动的灰度发布和放弃:理论上这是可行的,而且实践中确实也有人已经这样做了。也许,自动调参会是更激进,也更有用的。
了解时间周期效应:在一天的不同时段,或者一周的不同日期,用户行为可能会有很大的差异。因此即使你有足够的流量,最好也要让实验运行数个整天,或者数个整周。
实验的评价标准一定要在实验之前就确定:呵呵,又一次见到这条,这件事确实非常值得强调,而且在很多地方很遗憾地没有被遵守。另外,作者在这里更多强调的是实验各方应当对此达成一致,也就是说在实验前就统一认识,确认哪些指标的变化是符合预期的。为了解决类似的问题,我们在以后的文章中可能会见到另一种方法,通过一个权威机构“实验委员会”来最终解释实验。
基本情况:
基本操作
单集群场景
多集群场景-In a region
多集群场景-Across Region
单机优化
ceph是一个支持大量小文件和随读写的分布式文件系统。笔者这两天读过ceph的论文,在这里总结一下它的设计要点。由于能力所限,加之信息来源主要是ceph的论文,部分细节脑补,对代码和实际部署并没有经验,如有纰漏烦请指教。
本文假设读者有一定分布式存储系统经验,至少了解hdfs+hbase和dynamo这两种模型,因为ceph用到的各种奇技淫巧在这些系统中都能找到影子。
Ceph分为对象存储(RADOS)和文件存储(MDS)两层。对象存储层是基础,提供可靠的K/V对存储服务。文件存储层则提供POSIX语义的目录和文件服务。本篇博文将主要介绍RADOS。

* 来自ceph作者论文
RADOS有以下特点:
– 高可用(不受限于单点或几台master)
– 轻量级master
– 支持海量小对象
– 强一致
– 并发写
数据分布(Placement)
先从数据分布说起。RADOS中的对象由对象池(pool)管理。每个池中的所有对象都有同样的副本份数,分布规则等,这些信息缓存在客户端中。用户在存取对象时需要指定池的名字。
从对象的key到最终存储数据的服务器要经过两层映射(存储节点称为OSD)。首先是经过一个哈希函数把key映射到Placement Group(简称PG)。PG类似其它系统中于虚拟分区的概念,一个PG存放多个对象,每个存储节点有上百个PG。
第二层是通过一致性哈希函数CRUSH从PGID映射到到实际存放数据的主机,对于给定PGID和副本数量,CRUSH会生成副本位置信息。其中第一个副本是主,其它为从。主副本负责接收来自客户端的写,产生日志同步给从副本。如果出现多个客户端并发写,主副本也扮演协调者决定并发写的顺序。
当少量机器发生宕机时,作为一致性哈希函数,CRUSH产生的PG副本的位置不会有很大改别。同时,缺失数据的其它副本散落在整个集群,这就保证了补齐副本数据时可以利用整个集群的网络带宽。
监控节点(Monitor)
除了存储节点外,还有一些监控节点组成小集群,负责监控存储节点的运行状态。多个监控节点通过Paxos协议达到一致和保持数据冗余。监控节点上只记录epoch序号和一些全局状态(如是存储节点否在线、地址端口等),可谓相当轻量。每当监测到存储节点发生变更时,如机器上线或下线,将epoch序号增加以区别先前的状态。所有存储节点的状态信息称为ClusterMap。
计算CRUSH时需要利用ClusterMap,因此它被缓存在客户端或者存储节点上(因为轻量),用epoch序号识别缓存的数据是否过期。系统中所有的通信都携带epoch序号,这样新产生的epoch序号就能快速扩散到整个集群。
存储节点(OSD)
存储节点真正响应用户的读写请求。假设三份副本,用户将写请求首先发送给主PG副本所在的存储节点上,称为A,而后A再将数据以日志的形式并行发送给从副本B和C。即用户写A,A同时写B和C。待B和C返回结果给A后,A才能最后告诉用户写成功。副本之间是强一致的。
当有存储节点发生宕机时,监控节点发现后更新epoch和ClusterMap,并将最新的ClusterMap推送给存储节点。宕机的发现和ClusterMap的推送都是通过gossip p2p的方式完成的。存储节点重新计算CRUSH。由于有机器宕机,有一些副本会丢失主副本,这时CRUSH重新产生的第一个副本就变成主副本。新的副本寻找旧副本要求复制数据。由地一致性哈希的特性,发生变更的PG不会很多。
考虑这样一个场景:CRUSH产生的新副本和旧副本完全没有重叠。当用户正在写一组旧副本,旧副本全然不知新副本的存在,岂不是会脑裂?解法是新副本在能服务前,一定需要找旧副本复制数据。还记得前文说到所有通信都携带epoch序号吗,这样旧副本就会意识到自己该停止服务了。
在PG上的所有写操作由””两部分组成,v在PG内递增。这样可以保证新PG上的写总是覆盖旧PG。
另一个相似的场景是读脏数据的问题:用户1读旧副本,同时用户2并发写新副本。解决之道是禁止这样的情况出现。同一PG组内的所有副本两两互发心跳维持租约,假设三副本,如果副本A一段时间未接到B或C发来的心跳,那么A就自己判断已经失去联系。新副本开始服务前,也要等足够时间使旧副本的租约失效。由于通信传播epoch号,旧副本或者发现自己的ClusterMap过期,或者被网络隔离就坐等租约失效,总是可以保证强一致。
可用性
RADOS的一个设计亮点就是采用一致性哈希、轻量级监控节点的同时又保证强一致。CAP理论说高可用和强一致两者不可兼得。这里讲的高可用,实际上是和HDFS NameNode这种重量级master相比的。一旦过半数监控节点宕机,即master不可用,所有存储节点仍然可以正常服务读写。如果此时再有一台存储节点宕机,也只会出现和它相关的PG不能服务(假设n台存储节点,3份副本,那么受影响的PG占总体的1/(n-2))。
RADOS和dynamo的区别在于在PG副本不完整的情况下,禁止客户端读写(允许读会读到脏数据),直到宕机被监控节点发现才行。由此可见,监控节点对存储节点宕机的快速感知是至关重要的。若想在万台规模下做到十秒以内感知,即使不采用p2p的方式,也需要在监控节点和存储节点之间增加一层代理。
工程难度
Ceph最初是一个实验室项目,它的作者Sage Wail在这上面发表过几篇论文。他几乎是凭藉一人之力实现了整套存储系统(包括单机存储系统、小对象存储、文件命名空间、块存储、FUSE和内核模块)。查看git历史会发现90%的代码都是这他写的。这样的项目即使放到公司,也足够几十号人忙几年。
具体而言,笔者个人以为RADOS有以下难点:
1. 监控节点需要实现Paxos才能高可用,不用说Paxos有多少坑,看HDFS这么多年才搞出来NN真正的高可用
2. 支持随机修改让副本复制变得非常复杂,需要处理边写边追的情况
3. 规模!07年的论文就在讲百PB级别的存储(笔者认为这是扯淡,07年的硬盘多大),特别是系统中使用p2p通知和存储节点自主复制,p2p的测试要比简单master-slave模型难得多(master-slave的难点在于master高可用)。想想亚马逊那次宕机事故吧
参考资料:
Click to access weil-rados-pdsw07.pdf
Click to access weil-thesis.pdf
今天终于写到LevelDB最有意思的部分了。我们知道,在经典的merge-dump系统查询数据,运气差时可能需要访问每个SSTable,才能找到需要的数据。虽然BloomFilter在概率上解决了这一问题,但付出的代价却是与key/value对数据成正比的内存使用量(例如每个key/value对占用两三个比特,主要取决于可以容忍的出错概率)。如果将经典的merge-dump系统比喻成链表的话,LevelDB则使用一种类似搜索树的方式精心排列好SSTable,让查询在树的每一层上只命中一个SSTable,从而极大减少磁盘寻道次数。
我们先从SSTable的产生来源开始说。生成SSTable的途径有两种:
1. MemTable内存满,溢写到磁盘
2. 将旧的SSTable”合并”成新的,优化寻道次数
第一种溢写出来的SSTable是在系统内存耗尽时被迫的写出来的,优化余地不大。LevelDB中的优化是作用在第二种途径产生的SSTable上。传统的merge-dump系统只是简单地选择将几个小的SSTable合并为一个大的,由于SSTable内部是类似B树的索引方式(当然是只读的),实际中最多随机寻道两三次,相比原先的几个小的SSTable可以显著减少寻道次数。
但是大文件带来的问题是下次合并时会不灵活:下次合并时,这个大文件要么整体参与合并,要么整体不参与合并,再也不能像几个小文件那样选择其中的几个放弃另外几个了。尽管有如此不灵活,但考虑到合并带来的好处--寻道次数一下从线性级变成了对数级,大家仍然会”义无反顾”地选择合并。
LevelDB走了另一条路:从多个文件”合并”到多个文件。SSTable按顺序地存储了很多key/value对,我们可以记下其中最小和小大的key。最小key和最大key组成一个区间,当在用户查询落在这个区间之外(即用户查询的key比SSTable中最小的key还要小、或者比最大的key还大),那么就自然不必在这个SSTable中继续查找。显然,当这个区间范围越小时,这个SSTable也就不容易被无效命中了。LevelDB正是利用这个特点,让每次”合并”产生区间不重叠的多个输出文件,这样一来这些小文件逻辑上与单个大文件无异,又可以增加灵活性,一举两得。

LevelDB将所有SSTable分为7层(level),下文称为第0层至第6层。MemTable溢写生成的SSTable放在第0层。除第0至外,第1至6层中,每层内的SSTable的最小key和最大key区间是不重叠的。这就保证用户查找到第1至6层的SSTable时每层最多只需读一个SSTable。
如何生成这样的文件布局?让我们回到最开始,只有MemTable溢写出的第0层。随着用户不断写入,第0层的文件越来越多,当超过4个时开始第0层到第1层的合并。类似的,当第1层的数据太多时就合并到第2层,依次类推。衡量某层数据多少的标准是,第0层是否多于4个文件,或者第i层数据总量大于(10^i) MB。每次合并向更高一层输出多个区间不重叠的文件。当进行第i层到第i+1层的合并时,如果第i+1层原先也有一些文件存在,那么在发生区间重叠时需要将这些文件一起合并。
LevelDB中所有SSTable都是固定2MB大小。假如用以覆盖key区间为底、占用空间为面积的矩形表示SSTable,应用以上规则不断整理数据,最终会形成上图中布局:每层的文件数和数据量呈指数增长,越高层的文件越偏向瘦高,即单个文件覆盖更小的key区间。
到这里,想必读者应该已经明白LevelDB名字的由来了。
